cross-view-image-synthesis
[Project] [Paper, CVPR 2018] [Paper, CVIU 2019]
Abstract
Learning to generate natural scenes has always been a challenging task in computer vision. It is even more painstaking when the generation is conditioned on images with drastically different views. This is mainly because understanding, corresponding, and transforming appearance and semantic information across the views is not trivial. In this paper, we attempt to solve the novel problem of cross-view image synthesis, aerial to street-view and vice versa, using conditional generative adversarial networks (cGAN). Two new architectures called Crossview Fork (X-Fork) and Crossview Sequential (X-Seq) are proposed to generate scenes with resolutions of 64x64 and 256x256 pixels. X-Fork architecture has a single discriminator and a single generator. The generator hallucinates both the image and its semantic segmentation in the target view. X-Seq architecture utilizes two cGANs. The first one generates the target image which is subsequently fed to the second cGAN for generating its corresponding semantic segmentation map. The feedback from the second cGAN helps the first cGAN generate sharper images. Both of our proposed architectures learn to generate natural images as well as their semantic segmentation maps. The proposed methods show that they are able to capture and maintain the true semantics of objects in source and target views better than the traditional image-to-image translation method which considers only the visual appearance of the scene. Extensive qualitative and quantitative evaluations support the effectiveness of our frameworks, compared to two state of the art methods, for natural scene generation across drastically different views.
Code
Our code is borrowed from pix2pix. The data loader is modified to handle images and semantic segmentation maps.
Setup
Getting Started
- Install torch and dependencies from https://github.com/torch/distro
- Install torch packages
nngraphanddisplayluarocks install nngraph luarocks install https://raw.githubusercontent.com/szym/display/master/display-scm-0.rockspec - Clone this repo:
git clone git@github.com:kregmi/cross-view-image-synthesis.git cd cross-view-image-synthesis - Training the model
DATA_ROOT=./datasets/AB_AsBs name=sample_images which_direction=a2g phase=sample th train_fork.lua - For CPU only training:
DATA_ROOT=./datasets/AB_AsBs name=sample_images which_direction=a2g phase=sample gpu=0 cudnn=0 th train_fork.lua - Testing the model:
DATA_ROOT=./datasets/AB_AsBs name=sample_images which_direction=a2g phase=sample which_epoch=35 th test_fork.luaThe test results will be saved to:
./results/sample_images/35_net_G_sample/images/.
Training and Test data
Datasets
The original datasets are available here:
Ground Truth semantic segmentation maps are not available for the Dayton (GT-CrossView) dataset. We used RefineNet trained on CityScapes for generating semantic segmentation maps and used them as Gound Truth segmaps in our experiments. Please cite their papers if you use the dataset. We have shared the segmentation maps of Dayton Dataset here Dayton SegMaps.
Segmentation maps for CVUSA dataset are available with the dataset. Please follow the instruction in this link to convert them to the segmaps used in this project.
Train/Test splits for Dayton Dataset can be downloaded from here Dayton.
For CVUSA dataset experiments, we used the same Train/Test split as provided in the dataset.
Generating Pairs
Refer to pix2pix for steps and code to generate pairs of images required for training/testing.
First concatenate the streetview and aerial images followed by concatenating their segmentation maps and finally concatenating them all along the columns. Each concatenated image file in the dataset will contain {A,B,As,Bs}, where A=streetview image, B=aerial image, As=segmentation map for streetview image, and Bs=segmentation map for aerial image.
Train
DATA_ROOT=/path/to/data/ name=expt_name which_direction=a2g th train_fork.lua
Switch a2g to g2a to train in opposite direction.
Models are saved to ./checkpoints/expt_name (can be changed by passing checkpoint_dir=your_dir in train_fork.lua).
See opt in train_fork.lua for additional training options.
Test
DATA_ROOT=/path/to/data/ name=expt_name which_direction=a2g phase=val th test_fork.lua
This will run the model named expt_name in direction a2g on all images in /path/to/data/val.
Result images, and a webpage to view them, are saved to ./results/expt_name (can be changed by passing results_dir=your_dir in test_fork.lua).
See opt in test_fork.lua for additional testing options.
Models
Pretrained models can be downloaded here.
Place the models in ./checkpoints/ after the download has finished.
Results
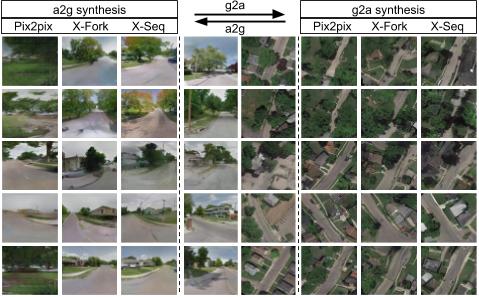
Some qualitative results on GT-CrossView Dataset:
CVPR Poster
Citation
If you find our works useful for your research, please cite the following papers:
- Cross-View Image Synthesis Using Conditional GANs, CVPR 2018 pdf, bibtex
- Cross-view image synthesis using geometry-guided conditional GANs, CVIU 2019 pdf, bibtex
Questions
Please contact: ‘krishna.regmi7@gmail.com’